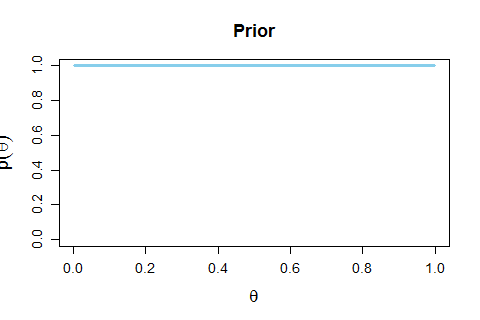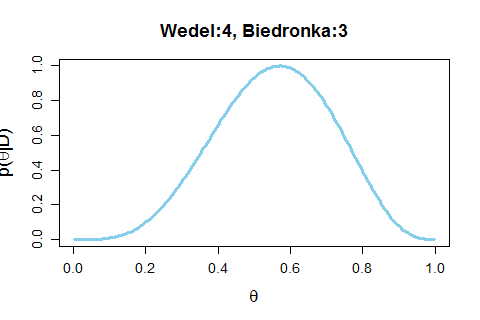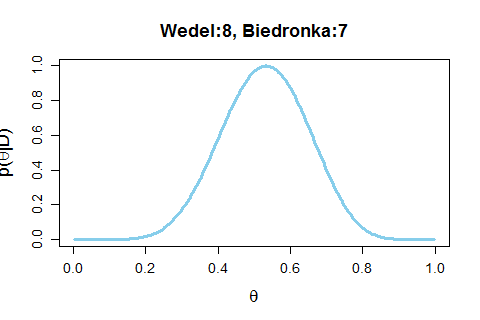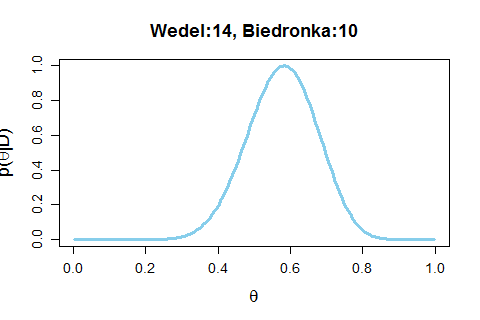
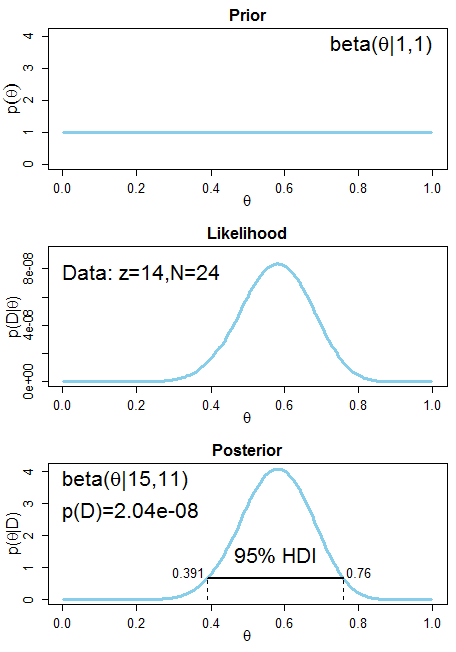
Nie mam i nigdy nie miałem nic wspólnego z biostatystyką, a głównym powodem, dla którego uczestniczę w kursie jest obecność nazwiska Bayes w sylabusie.
Muszę powiedzieć, że prowadzący Scott Zeger już w pierwszym wykładzie w bardzo przystępny sposób omówił ideę wnioskowania Bayesowskiego - narzędzia, którego używam na tym blogu do oceny niepewności wyników sondaży.
Podoba mi się to tak bardzo, że pokrótce opiszę to niżej. Najpierw przypomnę jednak o pierwszym oraz drugim wpisie o metodologii, na które warto rzucić okiem przed dalszym czytaniem.
Eksperyment polega na trzykrotnym rzucie nieznaną monetą. Nie wiemy jednak (i nie możemy podejrzeć) jak ta moneta wygląda - czy ma orzełka i na odwrocie reszkę, czy może jest podrobiona i obie strony monety mają orzełka, a może w ogóle nie ma na niej orzełka?
Stawiamy trzy hipotezy:
- H1: moneta nie ma strony z orzełkiem (z obu stron są reszki)
- H2: moneta ma dokładnie jedną stronę z orzełkiem (jest to zwykła moneta)
- H3: moneta ma obie strony z orzełkiem
Zaczynamy od założeń a priori. Tutaj wyrażamy nasze przekonanie, własną opinię, wiedzę wyniesioną z innych eksperymentów, itp. To oczywiście nie jest obiektywne, i wcale nie ma takie być. Założenia a priori będą zweryfikowane przez dane. Jeśli mamy wystarczająco dużo danych, to założenia a priori są nieistotne.
Powiedzmy, że sądzimy, że na 90% do eksperymentu została użyta zwykła uczciwa moneta. Z takimi spotykamy się na najczęściej. Pozostałym hipotezom możemy przypisać po 5% prawdopodobieństwa. Jest mała szansa, żeby jakieś dziwne monety trafiły do naszego portfela, ale trudno to wykluczyć. W końcu moneta to tylko kawałek metalu z wyciśniętym wzorem.
Teraz wykonujemy eksperyment i... dostaliśmy w wyniku trzy orły.
Hipotezę H1 odrzucamy natychmiast. Moneta ma przynajmniej jednego orzełka.
Dla uczciwej monety (tzn. o ile hipoteza H2 jest prawdziwa) prawdopodobieństwo wyrzucenia orła trzy razy pod rząd wynosi 1/2*1/2*1/2=1/8.
Jeżeli H3 jest prawdziwa, to prawdopodobieństwo takiego wyniku jest równe 1, bo nie ma innej możliwości niż wyrzucenie orła za każdym razem.
Zgodnie z regułą Bayesa możemy teraz aktualizować nasze przekonania co do prawdopodobieństw hipotez H2 (uczciwa moneta) i H3 (moneta z dwoma orłami).
Założenia a priori - prawdopodobieństwo, że hipoteza H2 (albo H3) jest prawdziwa:
P(H1) = 0,05
P(H2) = 0,9
P(H3) = 0,05
Likelihood (wiarogodność?) wyniku - prawdopodobieństwo zaobserwowania danych pod warunkiem, że hipoteza H2 (albo H3) jest prawdziwa.
P(Dane | H1) = 0
P(Dane | H2) = 1/8
P(Dane | H3) = 1
Prawdopodobieństwo zaobserwowania takiej serii danych:
P(Dane) = P(Dane|H1)*P(H1)+P(Dane|H2)*P(H2)+P(Dane|H3)*P(H3) = 0,1625
Teraz korzystamy z reguły Bayesa i aktualizujemy nasze przekonania:
P(H1 | Dane) = P(Dane | H1) * P(H1) / P(Dane) = 0
P(H2 | Dane) = P(Dane | H2) * P(H2) / P(Dane) = 0.6923
P(H3 | Dane) = P(Dane | H3) * P(H3) / P(Dane) = 0.3076
Co więc się stało i jak to zinterpretować?
Przed wykonaniem eksperymentu nasze zaufanie do tego, że moneta jest uczciwa wynosiło 90%. Było to bardzo prawdopodobne, bo większość monet, jakie widzimy jest uczciwa i ma orzełka na jednej stronie, a reszkę na drugiej.
Przed wykonaniem eksperymentu nasze zaufanie do tego, że moneta ma po obu stronach orła wynosiło 5%. To musi być jakaś specjalna moneta, ja takiej nie widziałem, ale nie wykluczam, że takie monety istnieją.
W wyniku eksperymentu dostaliśmy wynik - trzy orły pod rząd. To nowa wiedza i używamy jej do aktualizacji naszych przekonań.
Zastosowaliśmy regułę Bayesa i otrzymaliśmy wartości, jakie powinniśmy przyjąć jako miarę naszego zaufania. W świetle otrzymanych wyników nasze zaufanie do uczciwości monety powinno spaść do 69%, a podejrzenie, że moneta jest fałszywa wzrosnąć do 31%. Wiemy też, że nie ma możliwości aby moneta z obu stron nie miała orzełka.
Możemy teraz rzucać monetą dalej i ponownie zrewidować swoje przekonania.
Bez wchodzenia w techniczne szczegóły jest to dokładnie ta podstawowa zasada, której używam do analizy wyników sondaży w taki sposób, aby móc przedstawić stopień zaufania do wyniku danej partii.