Dziś trochę nie na serio. Pozwolę sobie na analizę głupot z sond ulicznych, jakie zaczęły się pojawiać na portalu gazeta.pl, za pomocą tych samych metod, których używam do sondaży wyborczych.
Pepsi vs Cola i przydługi wstęp
Pierwsza była próba napojów: czy lepszy smak ma Pepsi, czy Coca-Cola:Próba nie była losowa, nie była przeprowadzona w kontrolowanych warunkach, nie była podwójnie ślepa (prowadzący wiedział co jest w którym kubeczku) i można by mieć do niej jeszcze wiele innych zastrzeżeń.
Niemniej jednak zebrano dane: zapytano 11 osób, czterem osobom bardziej smakowała Pepsi, siedem wolało Coca-Colę (dla niecierpliwych: wyniki są od 2:51).
Czy coś nam to mówi? Wydaje się, że Coca-Cola jest zdecydowanie preferowana, bo woli ją prawie dwa razy więcej osób niż Pepsi.
Taki wybór między dwoma alternatywami można przełożyć na model, w którym wybieramy "1" albo "0". Jeśli do Coli przyporządkujemy zero, a do Pepsi jedynkę, to z tego badania mamy 4 obserwacje z jedynką i 7 obserwacji z zerem. Wartość oczekiwana wynosi więc (4*1+7*0)/11 = 4/11 ≈ 0,36. Dalej będziemy nazywali tę wielkość parametrem. Gdyby wszyscy wybrali Pepsi, to parametr byłby równy 1, gdyby wszyscy wybrali Colę, to parametr byłby równy 0. W sytuacji gdy oba napoje wybiera taka sama liczba osób i poparcie rozkłada się po połowie parametr byłby równy 0,5.
(Tym, którzy nadal czytają i jeszcze się nie boją proponuję wyszukanie sobie w tym momencie hasła "proces Bernoulliego")
Powiemy, że jeden z napojów jest istotnie chętniej wybierany, jeśli wielkość parametru będzie daleko od wartości 0,5 - blisko zera albo blisko jedynki.
Wartość 0,36 jest bliżej zera niż jedynki, więc skłaniamy się, ku zdaniu, że Cola smakuje ankietowanym lepiej.
Ale czy jest to istotna różnica?
Prosta analiza Bayesowska dałaby nam wykresy takie, jak poniżej:

Na górnym wykresie mamy naszą wiedzę przed wykonaniem badania, a priori. Niczego nie wiemy, więc każda wartość parametru pomiędzy 0 i 1 jest jednakowo prawdopodobna.
Na środkowym panelu przedstawiona jest funkcja wiarogodności wynikająca z zaobserwowanych danych: 11 obserwacji, z których 4 wybrały 1 (Pepsi).
Na dolnym panelu jest przedstawiona wiedza o parametrze po wykonaniu badania - po aktualizacji wiedzy a priori o informację wynikającą z danych, zgodnie z regułą Bayesa.
Mamy tu informację, że jest bardzo mało prawdopodobne, aby wszyscy lubili Colę (blisko zera wartość funkcji spada do zera). Jest też bardzo mało prawdopodobne, aby wszyscy lubili Pepsi (wartość funkcji jest bliska zeru również w otoczeniu jedynki). Maksimum funkcji znajduje się w punkcie 0,36 - równym wartości oczekiwanej parametru z naszych danych.
Patrząc inaczej na dolny wykres można pomyśleć, że jest to poziom naszego zaufania do tego, że parametr przyjmuje daną wartość po zebraniu takich odpowiedzi na ulicy. Im funkcja wyżej, tym bardziej ufamy, że właśnie taka wartość może być tą właściwą.
Typowym progiem istotności przy podawaniu wyników analizy statystycznej jest 95%. Wartość 95% została wyssana z palca osobiście przez Rolanda Fishera i tak już zostało do dziś. W powtarzalnych eksperymentach (np. testowanie żarówek na stacji kontroli jakości w fabryce) oznacza to, że pomylimy się średnio w 5% razy - raz na dwadzieścia prób.
Na dolnym panelu mamy wyrysowane również, w jakim przedziale na 95% znajduje się nasz parametr.
Są to wartości to od 0,14 do 0,64. Ten przedział obejmuje wartość 0,5 więc uwzględniając niepewność wynikającą z błędu statystycznego przy tej wielkości próby nie można powiedzieć, aby Cola była istotnie lepsza od Pepsi przy 95% przedziale wiarogodności.
Wielkość próby ma znaczenie. Gdyby odpytano nie 11, a 1100 osób i otrzymano takie same proporcje: 400 osób za Pepsi, 700 osób za Coca-Colą, to wnioski byłyby zupełnie inne. Wyżej wymieniony przedział, w którym na 95% jest nasz parametr byłby od 0,34 do 0,39. Nie ma w nim wartości 0,5, więc moglibyśmy zdecydowanie stwierdzić, że Cola jest wybierana częściej.
Ale nie ma 1100 obserwacji, tylko jest ich nadal 11.
Mógłbym też przeprowadzić taką analizę w identyczny sposób, jak traktuję dane z sondaży i otrzymać poniższe wykresy:

Uzbrojeni w wiedzę z tego przydługiego wstępu możemy szybko przejść do analizy pozostałych filmików.
Ptasie mleczko Wedel czy Biedronka?
Dla ciekawych wyniki od 2:37.
Zebrano 24 obserwacje, 14 osób wybrało produkt Wedla, 10 osób wolało pianki z Biedronki. W tym przypadku już na pierwszy rzut oka wydaje się, że różnica jest nieistotna.
Na poniższym wykresie 0 oznacza Biedronkę, a 1 - Wedla.
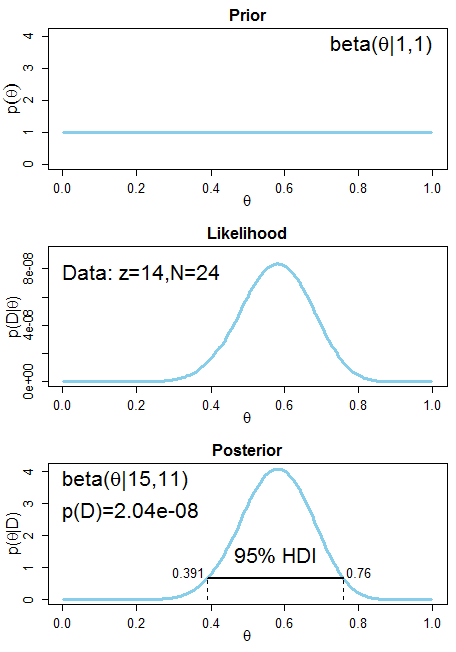
Tak, znowu otrzymaliśmy wynik posterior, który obejmuje wartość 0,5 - nie możemy więc powiedzieć, że różnica jest istotna.
Tak można inaczej przedstawić obserwacje i rozrzut wynikający z błędu statystycznego i nikłej wielkości próby:

Przewaga Wedla nie jest istotnie różna od zera.
Frytki KFC i McDonald's
Oto filmik, wyniki dla niecierpliwych są w 2:59
Tym razem jest 20 obserwacji, cztery osoby wybrały KFC, a 16 wolało McDonald's. Nie było odpowiedzi "żadne, frytki są niejadalne" - a to byłby mój wybór.
KFC zakodowałem jako zero, a McDonald's jako jeden. Wyniki z analizy bayesowskiej wyglądają tak:

O, i to już jest coś zupełnie innego. Cały wykres posterior jest przesunięty w prawo, w stronę McDonald's. Co więcej, obszar 95% masy gęstości tej funkcji nie obejmuje wartości 0,5 - zaczyna się od 0,6.
Możemy więc powiedzieć, że frytki z McDonald's były wybierane istotnie częściej niż te z KFC przy 95% poziomie wiarogodności.
Oto jak te same wyniki wyglądałyby na wykresach pudełkowych:

Przewaga jest istotna statystycznie i mamy potwierdzenie tego na wykresach.
Brak komentarzy:
Prześlij komentarz