Dla przypomnienia, wróćmy do przykładu ptasiego mleczka od Wedla i pianek z Biedronki. Na ulicy zapytano osoby, które pianki wolą, były 24 obserwacje, 14 osób wskazało Wedla, 10 wolało te z Biedronki.
Przedstawiłem tam taki wykres:

Patrząc inaczej na dolny wykres można pomyśleć, że jest to poziom naszego zaufania do tego, że parametr przyjmuje daną wartość po zebraniu takich odpowiedzi na ulicy. Im funkcja wyżej, tym bardziej ufamy, że właśnie taka wartość może być tą właściwą.Pomyślałem sobie, że dla kogoś (większości), która nie ma z tym do czynienia warto byłoby pokazać na animacji w jaki sposób zmienia się zaufanie co do tego, gdzie znajduje się poszukiwany parametr, czyli to, co znajduje się na dolnym panelu powyższego wykresu.
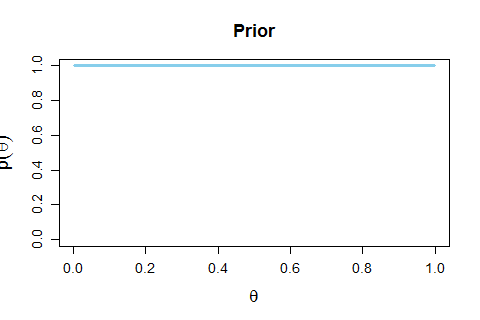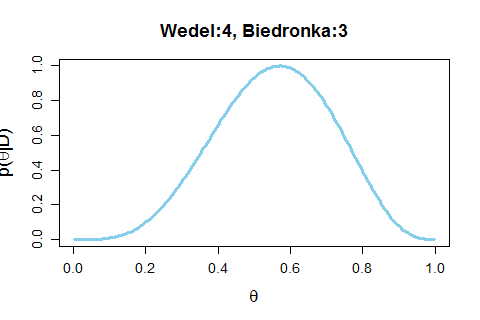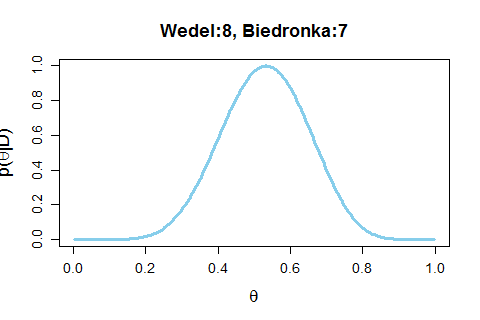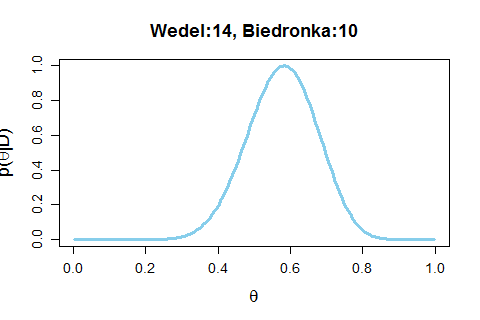
Następnie jedna obserwacja po drugiej dodawałem do modelu wiedzę - w takiej samej kolejności, w jakiej odpowiadały osoby na filmiku. Na wykresie widzimy jak ta nowa wiedza wpływa na nasze zaufanie do położenia przedziału, w którym jest wartość parametru
Widzimy jak zmienia się przedział, w którym funkcja przyjmuje duże wartości. Kiedy liczba głosów na obie możliwości jest równa, to funkcja rozkłada się symetrycznie wokół wartości 0,5. Ale im więcej mamy obserwacji, tym "górka" jest węższa. Przypominam, że głosy dla Biedronki były kodowane jako zero, a głosy dla Wedla jako jedynka. Im więc "górka" funkcji bliżej zera, tym bardziej jesteśmy przekonani o tym, że Biedronka jest wybierana częściej.
Kolejność dodawania obserwacji nie ma znaczenia dla ostatecznego wyniku. Liczy się tylko zdobyta z danych informacja.
Oto analogiczna animacja dla filmiku o frytkach. Tutaj frytki z KFC są zakodowane jako zero, a wyrób z McDonald's jako jedynka.

No i po co to wszystko?
Uznałem, że te bardzo proste przykłady będą dobrym nie-matematycznym podsumowaniem tego, co robię na koniec miesiąca we wpisach o agregacji sondaży, jak na przykład w tym na koniec czerwca.Zasada jest dokładnie taka sama. Zaczynam od pewnego rozkładu a priori i pozwalam, aby dane aktualizowały model. Na animacji poniżej znajduje się wizualizacja uproszczonego modelu, w którym pracownia nie jest czynnikiem.
Są to wyniki poprzedniego sondażu TNS. Tutaj przedstawiony jest model, zawierający oprócz ugrupowań również opcje "nie idę" oraz "inne". TNS nie podaje wielkości próby, założone było 1000 osób i frekwencja 59% - czyli opcja "nie idę" powinna być wybierana średnio przez 41% respondentów.
Tak wyglądają wykresy po 100 obserwacjach:



A o to cała animacja.
Czerwone linie to przedziały, w których znajduje się 95% masy prawdopodobieństwa. To odpowiedniki pudełek z wykresów znanych z innych wpisów.
Myślę, że ciekawe jest patrzeć na to, jak zmieniają się te wyniki. Wydaje się, że już przy 100 wywiadach generalny układ wyników jest ukształtowany, a od 500 obserwacji zmiany są tylko kosmetyczne.
To powód, aby innym razem wrócić do tych wykresów i napisać więcej o wielkości próby.
Brak komentarzy:
Prześlij komentarz